

Diff-DAC: fully distributed deep reinforcement learning
Here at Secondmind, we’re developing a multi-agent solution where agents need only to share their learned knowledge with their immediate neighbors for it to spread—or diffuse—to agents performing related tasks throughout a network, much as children in school pass on knowledge to each other.
Within a decade, tens of billions of interconnected devices will be processing and exchanging data throughout the global economy. AI agents that can make decisions— often in real time—will be needed to support increasingly intelligent networks of phones, devices, appliances, homes, vehicles, power grids, cities, and markets. The variety of tasks and technologies within these networks will require those agents to learn strategies and policies that generalize well across related tasks.
Fortunately, when the tasks that agents perform are similar, their optimal policies tend to be similar. When adjusting temperatures in a wireless network of thermostats, for instance, or setting meeting agendas via virtual assistants, tasks can be enough alike that they can be performed using similar policies. That said, small differences in tasks (for example, the size of a house or the position of an employee) can mean the optimal policy for one task might be suboptimal for another and require relearning the local policy. But we show that when we use diffusion to learn several related tasks in parallel, we find policies that generalize well.
One recent trend in reinforcement learning (RL) is to put multiple threads of data from similar tasks into a single buffer, from which a central/master/coordinator node can perform the whole learning process. This is the case for Asynchronous Advantage Actor Critic (A3C) and Distributed Proximal Policy Optimization (DPPO) algorithms.2 The learning process can then be performed centrally using a standard parallel computing approach. These multithreaded approaches are distributed for data gathering but not for learning, because the computations are performed at a central node.

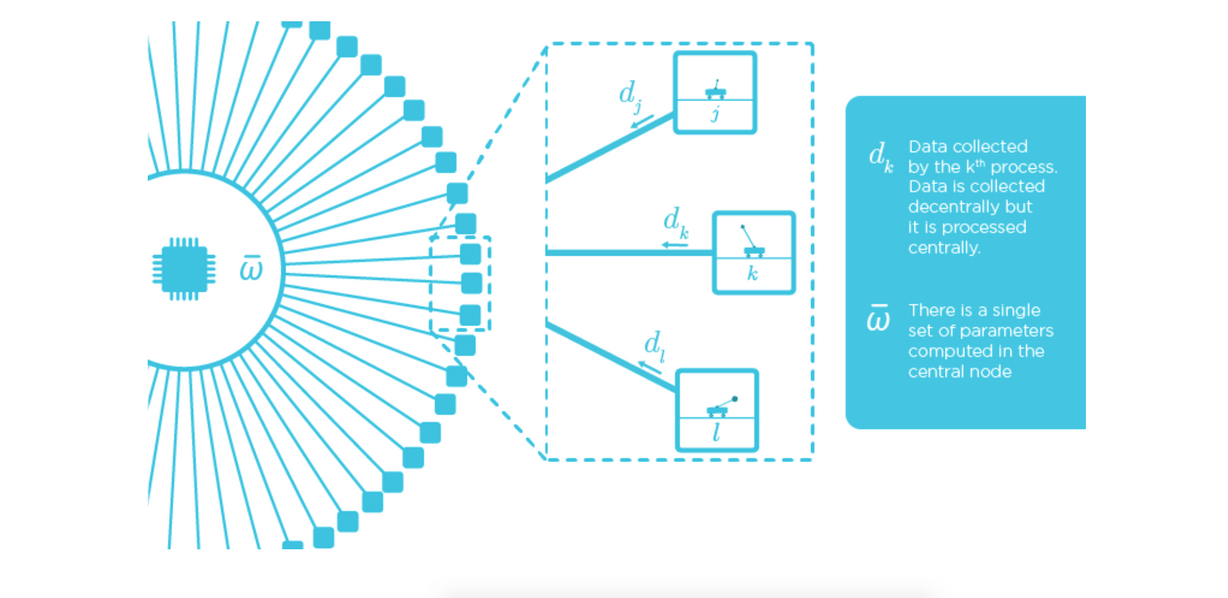
But we believe it is more efficient to process data where it was generated, and thus avoid the potentially high communication costs of transmission to a central node.
Our multi-agent approach doesn’t require a central node because the agents use diffusion to transfer knowledge.3 Diffusion enables agents to learn as if they had access to all data from all other agents, but without having to communicate a single data sample. The agents can be sparsely connected (with a path between any pair of nodes) and communication is locally executed between neighbors; expensive message forwarding is not allowed (see Figure 2, where agent k exchanges parameters only with its neighbors, j and l). This approach is inspired by biological systems—like synchronized fireflies or murmurations of swallows—where sparse networks are natural and the decision-making process is distributed among self-organized entities.
In the absence of central processing, the agents learn independently and then share some intermediate parameters with their neighbors to include them in a “diffusion update rule". By communicating with each other, nearby agents tend towards consensus. As information is diffused across the network, every agent benefits from every other agent's learning process. Because agents can communicate only with their neighbors, the computational complexity and communication overhead per agent grow linearly with the number of neighbors instead of the total number of agents. This allows diffusion algorithms to scale well to very large networks.
Another significant benefit is that diffusion can offer better solutions for hard nonconvex problems.3 Because diffusion algorithms run multiple (one per agent) interacting optimizers, each with a different initial condition, they can pull each other away from poor local optima. The numerical experiments suggest this approach is usually more effective than running a single optimizer multiple times, as is typically done in centralized approaches.
Our approach can also improve multitask learning (MTL), which tries to solve multiple tasks at the same time by exploiting their commonalities. Because most traditional MTL methods require central access to data from all tasks, they suffer when tasks are geographically distributed or subject to privacy concerns. Diffusion can avoid the problems and costs inherent in transmitting data between a large number of tasks and a central station, especially when the network is sparse.
Moreover, diffusion is resilient in cases of agent or communication link failure. If some agents are disconnected from the network, they can still learn by themselves and benefit from the learning processes of their connected neighbors. In a centralized architecture, in contrast, if the central node fails, the whole network becomes inoperative.
In our paper, we have leveraged diffusion to propose Diffusion Distributed Actor Critic (Diff-DAC), a novel actor-critic method that is distributed in both the data-gathering and learning stages. We use neural networks as function approximators for the policies. Even though they require parameter tuning and are usually sample-inefficient, neural networks can automatically discover useful features from the data. The optimizers stabilize each other and learn without an experience replay buffer or target networks—reducing the number of required hyperparameters—and they tend to achieve better policies than centralized or partially distributed actor-critic algorithms like A3C.
In order to derive Diff-DAC from first principles, we express distributed reinforcement learning as the optimization of the sum of all agents’ individual objectives. We obtained this formulation by re-deriving the actor-critic framework as a saddle-point problem, in a way that extends previous intuitions.5 This provides new theoretical insights by connecting the actor-critic framework with the standard dual-ascent method from convex optimization theory.
The paper evaluates the benefits of Diff-DAC in a number of experiments in benchmark problems such as “cart-pole balance”, “inverted pendulum”, and “cart-pole swing-up”, and we aimed to answer the following questions:
- Is Diff-DAC, which allows agent access to only a small subset of the data, able to achieve the same performance as a centralized architecture with access to all data from all tasks?
- Is deep reinforcement learning able to find a single policy that is expressive enough to perform well for similar tasks?
- Is Diff-DAC able to scale to large networks?
Diff-DAC achieved state-of-the-art results for these benchmarks. It was able to match and usually outperform the results obtained with the centralized architecture. The single learned policy was expressive enough to outperform a previous state-of-the-art distributed MTL approach that considered one linear policy per task. We tried different network topologies for connecting agents and the results scaled well, remaining relatively independent of network size and sparsity.
In conclusion, we believe diffusion is a useful technique for deep reinforcement learning. It can be added to any value function or policy search update (DQN, DDPG, PPO, etc.) to improve robustness and reliability. It can be used for both single and multitask learning. Though the agents in the paper learn a single common policy, the Diff-DAC approach can naturally be extended to MTL with individual, specialized, task-dependent policies. Finally, Diff-DAC can be extended to game-theoretic settings, where agents interact with each other in the same environment. There is a lot of very exciting new work in this area, and we look forward to publishing further results.
Notes
- M. E Taylor and P. Stone, 2009. Transfer learning for reinforcement learning domains: A survey. Journal of Machine Learning Research 10(Jul):1633–1685.
- V. Mnih et al., "Asynchronous methods for deep reinforcement learning." International Conference on Machine Learning (2016); and N. Heess et al. "Emergence of locomotion behaviours in rich environments." arXiv preprint arXiv:1707.02286 (2017).
- A. H. Sayed, 2014. Adaptation, learning, and optimization over networks. Foundations and Trends in Machine Learning 7(4-5):311–801.
- S. Valcarcel Macua, 2017. Distributed optimization, control and learning in multi-agent networks. PhD Dissertation, Universidad Politécnica de Madrid. (Sec. 4.7 - 4.8).
- D. Pfau and O. Vinyals. "Connecting generative adversarial networks and actor-critic methods." arXiv preprint arXiv:1610.01945 (2016).