

What is Stochastic Network Control?
How can you make the best business decisions to optimize the balance between cost and quality? Most organizations apply a trade-off between their cost and service levels, where they try to find the sweet spot to maximize both their returns and their customers’ experience.
In reality, finding the right trade-off is an extremely difficult undertaking. The networks most businesses operate in are highly complex, and both large and small disruptions can destroy the best-made plans.
Stochastic Network Control (SNC) is one way of approaching a particular class of decision-making problems by using model-based reinforcement learning techniques. These techniques use probabilistic modeling to estimate the network and its environment. We also incorporate stochastic optimal control theory to find the optimal policy. In this post, we’re going to explain what SNC is, and describe our work in this field to help businesses optimize their decision-making processes.
What is SNC?
SNC tackles optimal sequential decision-making over a class of networks that consist of queues (sometimes called buffers in the literature) and resources that can drain the queues, moving their content to other queues or out of the network entirely.
These problems arise in many real-world scenarios and systems. For example, imagine a factory floor. We can model the production line as a network of processes:
- The demand arrives as orders from customers.
- The factory orders raw material from its supplier (which is also a resource).
- The raw material arrives at the factory and is stored ready to be processed (the place where it is stored can be modeled as a queue).
- This raw material is then processed by some operator and/or machine (also a resource) to produce some intermediate products.
- These intermediate products are then moved to another place (another queue) ready to be processed further or stored until they are needed.
- Depending on the complexity of the final product, there might be many different queues and resources.
This is just one example of an SNC problem. You can extend this class of problems to any network where we are managing queues and resources.
For example, imagine a hospital where a patient arrives and has to wait in the emergency room (queue), while other patients arrive in different departments (representing other queues). The hospital is filled with doctors and nursing staff (resources) who attend the patients (draining the queues) and decide what test or treatment to prescribe. This decision moves the patient to another queue until a doctor or nurse completes the required test or treatment.

Our road transportation networks are another example, where cars arrive at intersections (queues) and wait until the traffic lights (resources) allow them to move. Cloud computing and telecommunication networks are further examples where resources have to schedule, process, and send jobs or packets across the network.
However, we also need to take into account the fact that different queues have different costs. For example, a patient waiting in a hospital emergency room is in more danger (high cost) than someone waiting for a routine blood test (low cost). Likewise, it costs more (from a financial perspective) to store products in a high-street store than an out-of-town warehouse.
What’s more, different actions have different costs. For example, you might decide to take the toll road to reduce your journey time—but you have to pay money to use the road.
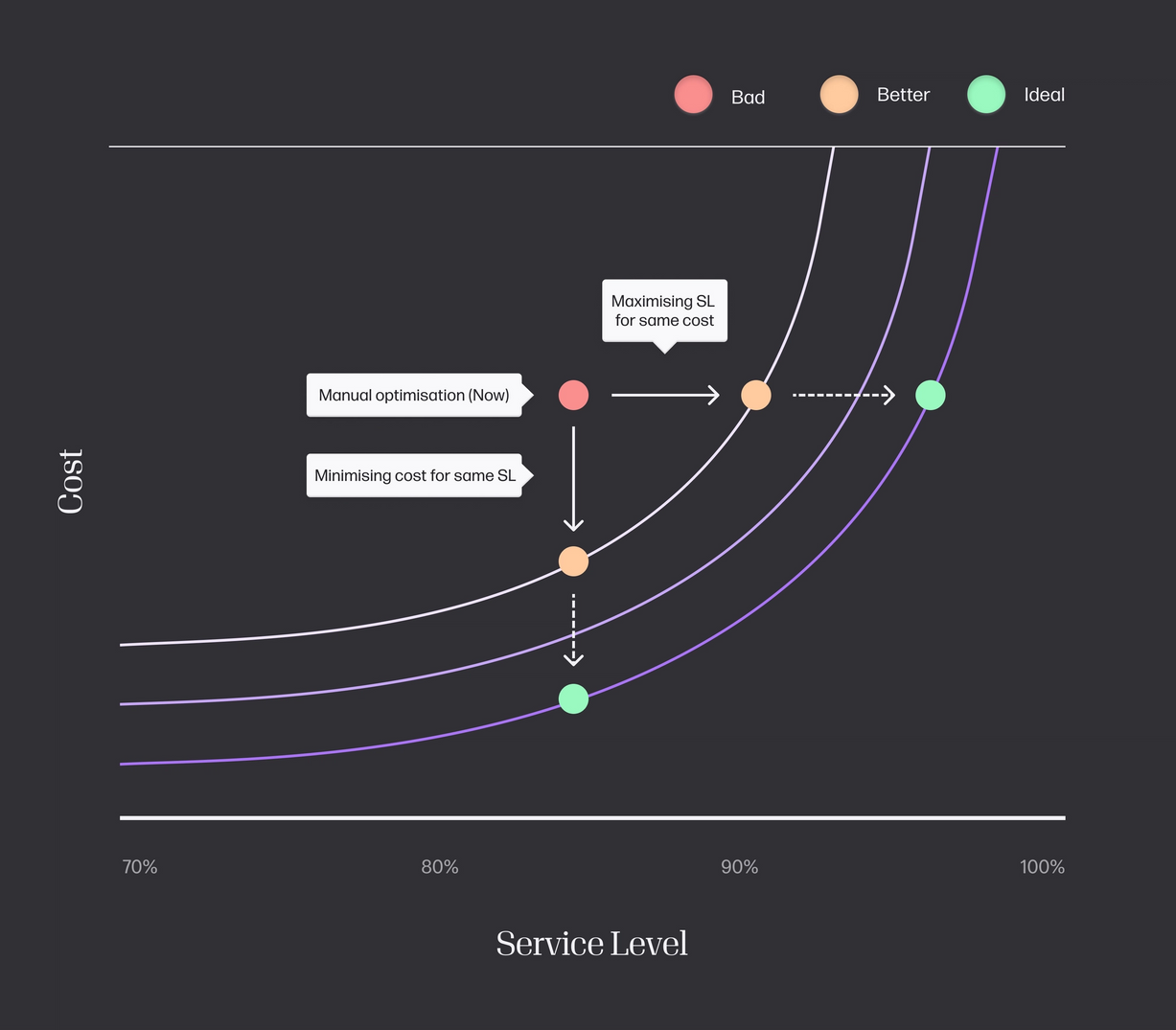
As you can see, with all of these problems, the goal is twofold. On the one hand, we want to minimize the cost of operating the network by reducing storage costs, transportation costs and so on. On the other hand, we want to maximize some notion of quality, which, for our supply chain applications, is usually equivalent to delivering orders to customers without delay (representing service or demand satisfaction level).
But there’s a problem. Minimizing cost and maximizing quality are two opposite criteria. If we reduce the cost too much, we cannot achieve high quality. So, we need to find a trade-off or fix one criterion and optimize the other. For example, we could decide to minimize the cost as long as we satisfy 99% of the demand.
Why trade-offs are difficult
On the surface, finding your optimal policy might not sound too difficult. However, queues and resources are connected because any local decision taken by a single resource will influence other parts of the network. Similarly, any instantaneous decision taken at any time will influence the future.
Another key difficulty is that events in these networks are often stochastic. This means, for example, that the same job sometimes takes longer than others, and that customers arrive whenever they want.
SNC aims to derive policies that indicate the actions that every resource has to take so that the network achieves an optimal trade-off of long-term cost and quality.
To achieve this, we need to take into account the current (stochastic) state of the network, to consider the network holistically (as opposed to locally), and to consider the long term reach of each action (as opposed to its instantaneous consequence).
Tackling trade-offs with machine learning
The Operations Research (OR) community has been tackling operational SNC problems for decades across a range of industries and applications, including supply chain problems. There are domain-specific algorithms for simple instances of the problem class; these algorithms typically tackle only a part of the problem (resource scheduling, inventory routing, stocking policies, and so on) independently of the others.
Nowadays, the AI community recognizes sequential decision-making as an important and difficult problem. That is one of the reasons why the field of reinforcement learning is experiencing a big surge in popularity. Reinforcement learning aims to achieve the same optimal long-term cost-quality tradeoff that we discussed above.
However, there is an extra feature that can make it very challenging for standard reinforcement learning algorithms to control stochastic networks. This is the network load. In a heavily loaded network, the resources need to operate at near-maximum capacity most of the time. So, there is little room for distraction and exploration before the network becomes unstable.
Imagine, for instance, a traffic intersection. If only a few cars are waiting, it doesn’t really matter if one car is a bit distracted and takes ten seconds to start moving again; the other cars will likely be able to pass before the traffic light turns red again. However, if the traffic is heavy, any small delay can propagate to, and be amplified by, other cars, creating a traffic jam. Therefore, a standard model-free reinforcement learning (RL) algorithm, which has to explore in order to learn, will generally struggle to learn to control these highly strained networks.
Moreover, a heavily loaded network will spend most of its resources in attending to the continuous arrival of new items (orders, customers, jobs, cars, and so on). If for any reason the buffers become full, it will take a significant amount of time to process the items in the network, with little extra capacity available to the resources after attending to the continuously incoming demand. Because most of the changes in the buffer lengths are driven mainly by the random arrivals, this introduces another real challenge for standard model-free RL algorithms, which will struggle to learn how their actions affect the changes in the buffer lengths and the associated costs. This is known as the ‘credit assignment problem’ in the RL literature, and it can become really challenging in the heavy load regime.
Another challenge for a standard model-free RL algorithm is that it operates well only if the environment doesn’t change. If something changes, the algorithm has to be trained again. So, if any disruption occurs, like resource failures, a standard RL algorithm cannot react.
What is unique to our SNC research is that we are tackling sequential decision-making problems for stochastic networks, even when they are complex and heavily loaded, and even when they suffer disruptions. To my knowledge, there is no other algorithm that can do this.
Inside our algorithm
Let’s outline how our algorithm achieves this. First, we start with some prior knowledge of the network. This includes:
- How resources and queues are connected: basically, which resources can drain which queues, and where the items/customers/patients/jobs go when they leave each queue.
- The operating costs: for example, the costs per item and per time step for every queue. If this is not known for some queues, then a relative value could be used, for example, if we know it is ten times more costly to store a product in one location compared to another.
- The demand rate and the time that takes to serve each queue: for example, the recorded history of the number of customers per month, an estimate of the lead time between the factory and the warehouse based on the distance, and so on.
This information constitutes what we call the system model. If such a model is uncertain, then we have to estimate it using probabilistic modeling techniques. This could be done online, so the model is continuously refined and can dynamically react to changes in the network.
Our current version of the algorithm can naturally handle unexpected peaks in demand, because this would be modeled as a change in the state which is already an input of the algorithm.
Moreover, our algorithm can react immediately (that is, without retraining) to multiple types of disruption, such as resource failures, or changes in the network connectivity, as long as the new system model is available to the algorithm.
Our algorithm can also be extended to take into account preventative maintenance, where some resources can be disabled for some time with minimum impact.
In conclusion
Given the model of the network, our algorithm observes the current state of the system and outputs the action that every resource should make in order to optimize the long term cost-quality tradeoff.
This work has far-reaching consequences for any organization that needs to optimize its trade-offs, and the industry it operates in. For example, in a recent use case for the logistics industry, Decision Engine could realise a potential 25% reduction in transport costs and tens of billions of dollars of identified cost savings across the global pool pallet industry by optimising pallet collection. SNC will continue to extend Decision Engine with further network control capabilities by simultaneously optimizing pallet collections, pallet deliveries, and pallet sharing among warehouses (rebalancing), for example.
At the current time, we’re working on an exciting new paper in the area of Stochastic Network Control. We’ll cover the specifics of that research in a future blog post.
Watch this space!
P.S - Thanks to Gemma Church, Sofia Ceppi, Egor Tiavlovsky, Patrick White and Alexandra Hayes for their insightful comments and discussions!